Visual Studio 編譯出 lib 檔案並使用
一般有分靜態函式檔案lib與動態函式檔案dll,簡單的區別方式就是使用的時機不一樣。
如果你今天是在寫程式,想要引入一個已經寫好的函式那麼需要的是lib,靜態指的就是編譯器在編譯的時候就把它納入了不能在做什麼更改了。
動態的則是編譯的時候並不需要它,而是等到程式編譯好之後在執行期可以動態載入或是取消,這樣的方式使用。
動態的則是編譯的時候並不需要它,而是等到程式編譯好之後在執行期可以動態載入或是取消,這樣的方式使用。
編寫lib主要好處有2個,第一個是不用重新編譯,如果程式碼很多的話每一次就重新編一全部都很耗費時間,先編好的這一個部分就不用再動它了,不過現代的編譯器都會自動做這個優化當你這一份檔案.cpp完全沒動編譯器就不管直接取上一次編譯的結果。
第二個則是隱藏的你的代馬,如果你寫了一個大程式其中有一部分核心代碼不想公開,或是整份都不想,這時候編譯成lib檔案,對方就沒辦法輕易獲得妳的代碼。
下面是用VisualStudio實作的範例
Visual Studio 編譯出 lib
先新建一個方案或專案
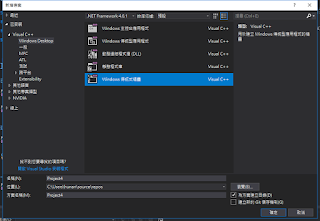

選擇lib,然後底下的
這樣可以建立空白專案(圖中截圖沒拍好)
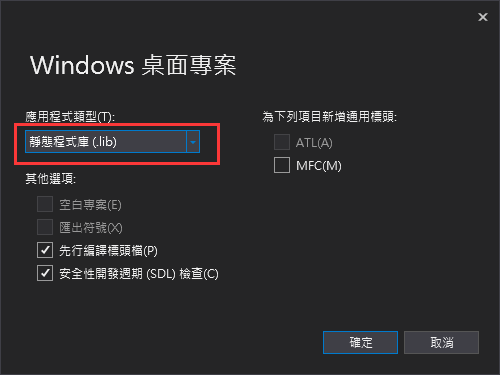
先行編譯標頭檔(P) 要取消打勾這樣可以建立空白專案(圖中截圖沒拍好)
然後新建這兩份檔案,檔案來源是微軟的教程
標頭檔
#pragma once
// MathFuncsLib.h
namespace MathFuncs
{
class MyMathFuncs
{
public:
// Returns a + b
static double Add(double a, double b);
// Returns a - b
static double Subtract(double a, double b);
// Returns a * b
static double Multiply(double a, double b);
// Returns a / b
static double Divide(double a, double b);
};
}
定義檔
// MathFuncsLib.cpp
// compile with: cl /c /EHsc MathFuncsLib.cpp
// post-build command: lib MathFuncsLib.obj
#include "MathFuncsLib.h"
#include <stdexcept>
#include <iostream>
using namespace std;
namespace MathFuncs
{
double MyMathFuncs::Add(double a, double b)
{
return a + b;
}
double MyMathFuncs::Subtract(double a, double b)
{
return a - b;
}
double MyMathFuncs::Multiply(double a, double b)
{
return a * b;
}
double MyMathFuncs::Divide(double a, double b)
{
return a / b;
}
}
新增完畢之後並不是按F5編譯,而是建置方案
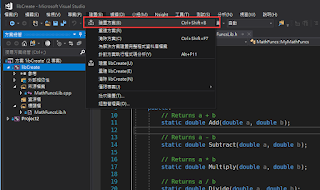

這一步驟執行完畢就會有lib檔案了,到專案資料夾去看
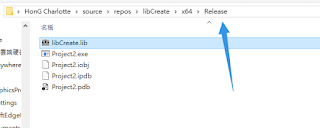

取出這個檔案 .lib 與 .h 就可以直接用了
測試檔案
我們可以在同一個方案裡面新增多個專方案,可以透過左邊看哪一個是粗體就是目前處理的方案,不過這個不是很明顯不好分辨就是了。

跟剛剛一樣選擇 傳統方案,然後這次選擇exe而不是lib,並且勾選空白專案。建立出一個新專案。
把新專案設置成主要
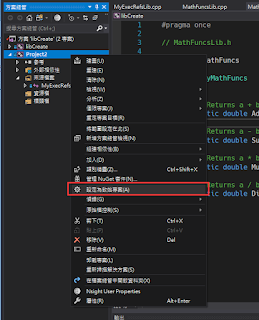

然後新增下面代碼(這裡一定要先新增一個cpp選項才會有東西)
// MyExecRefsLib.cpp
// compile with: cl /EHsc MyExecRefsLib.cpp /link MathFuncsLib.lib
#include <iostream>
#include "MathFuncsLib.h"
using namespace std;
int main()
{
double a = 7.4;
int b = 99;
cout << "a + b = " <<
MathFuncs::MyMathFuncs::Add(a, b) << endl;
cout << "a - b = " <<
MathFuncs::MyMathFuncs::Subtract(a, b) << endl;
cout << "a * b = " <<
MathFuncs::MyMathFuncs::Multiply(a, b) << endl;
cout << "a / b = " <<
MathFuncs::MyMathFuncs::Divide(a, b) << endl;
return 0;
}
到屬性內
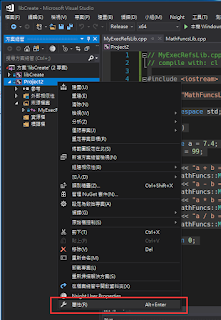

新增剛剛那個專案的那個.h檔的目錄
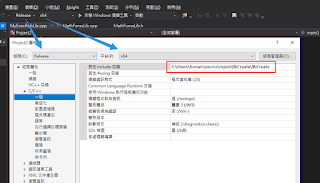

新增lib位置
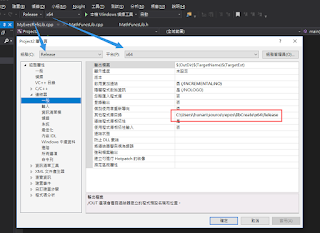

新增 lib 檔名
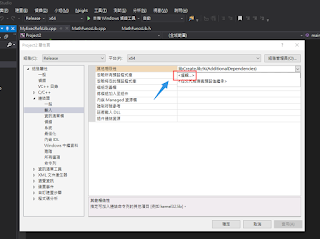


然後就編譯吧~就可以使用了
如果你要更改lib的內容就直接更改然後做這個動作重編即可,因為是直接引用邊出來的檔案,所以編譯之後就直接更改目標檔案了,這樣比較方便也不用開兩個vs視窗。

最後是這一次教程的文件,我把它上傳到github上了,可以自行下載測試。
https://github.com/hunandy14/libCreate
https://github.com/hunandy14/libCreate


















